● L2캐쉬까지를 포함한 CPU 코어 블록
Intel는, 4월 2~3일에 걸쳐 중국 상하이에서 개최되고 있는 기술 컨퍼런스「Intel Developer Forum(IDF)」에 두고, 차기 CPU 마이크로 아키텍쳐「Nehalem」의 개요를 발표했다.
Nehalem은 한마디로 설명하면, 현재의 Core Microarchitecture(Core MA)의 골격에, 새롭게 SMT(Simultaneous Multi-Threading)나 3계층의 캐쉬, 계층화한 Translation Lookaside Buffer (TLB)나 분기 예측 유닛을 시작해 다양한 기능을 더하는 것으로 CPU 코어의 퍼포먼스 업을 도모한 CPU다. 더하고, 고속 인터커넥트「QuickPath Interconnect(QPI)」라고 DDR3 DRAM 인터페이스를 내장해, 시스템 아키텍쳐를 개선했다.
전작 NetBurst(Pentium 4)로부터 Core MA에의 전환은, 마이크로 아키텍쳐의 기본 부분의 대혁신이었다. 그에 대하고, 이번 Core MA로부터 Nehalem에의 이행은, 기본 부분에서의 변화는 작지만, 다양한 테크닉을 구사하는 것으로, 대폭적인 퍼포먼스 업을 도모하고 있다.
Intel에 의하면, Nehalem의 골은, 유산 어플리케이션과 새로운 어플리케이션의 양쪽 모두를 고속화하는 것었다고 한다. 게다가, 퍼포먼스를 올릴 뿐만 아니라, 퍼포먼스/소비 전력도 향상시킨다. 게다가 제품화에서는 모바일이나 데스크탑 전용으로부터 서버까지 커버할 수 있도록 한다.
IDF의 기술 세션에서는, Nehalem의 CPU 코어 블록에는, CPU 코어 점유의 L2캐쉬도 포함되어 있는 것이 밝혀졌다. 즉, Nehalem에서는, 각 CPU 코어에 점유의 유닛 모두가, 장방형의 블록에 예쁘게 정리하고 있다. 그 때문에, CPU 코어 설계를 듀플리케이트 하는 것으로, 듀얼, 쿼드, 옥타까지의 멀티 코어 구성을 비교적 용이하게 설계할 수 있다.

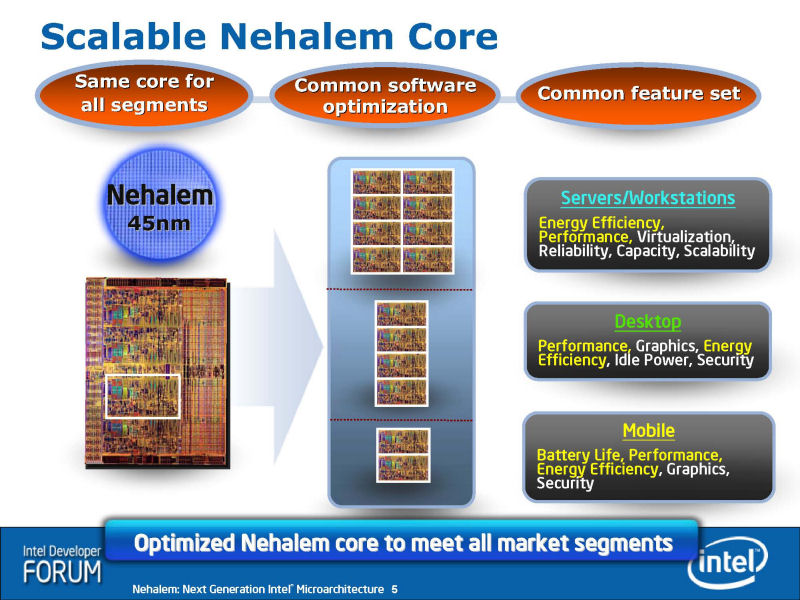
● 유사성의 강한 Core MA와 Nehalem의 블록 다이어그램도
위의 그림은, IDF로 나타난 Nehalem의 CPU 코어의 레이아웃이다. 이 차트에서는, 기능 블록의 분할이 그려져 있지만, 실은, 이것은 전혀 정확하지 않다. 잘 보면, 아래의 유닛의 경계와 전혀 일치하고 있지 않다. 어디까지나 개념도로 파악하면 좋겠다.
Nehalem로 확장된 주된 기능은, 다이 레이아웃의 주위에 쓰여져 있는 대로다.
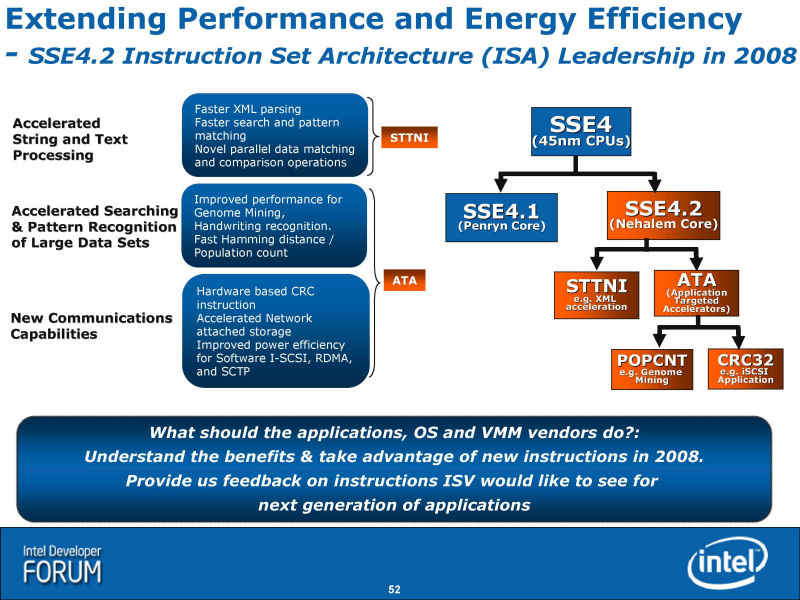
- New SSE4. 2 Instructions
- Improved Lock Support
- Additional Caching Hierarchy
- Deeper Buffers
- Improved Loop Streaming
- Simultaneous Multi-Threading
- Faster Virtualization
- Better Branch Prediction
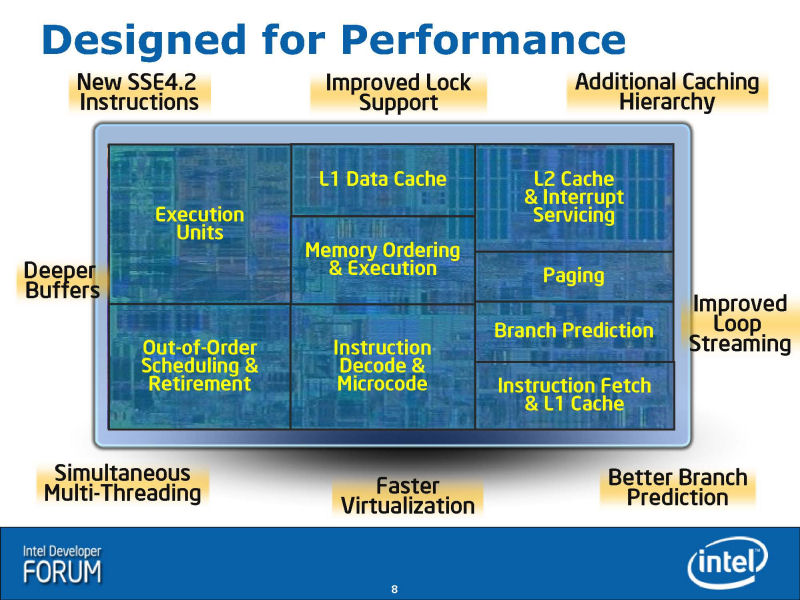
IDF에서는, Nehalem의 간단하고 쉬운 블록 다이어그램도도 공개되었다. 위의 슬라이드가 그것이다. 이 슬라이드를 베이스로, 다른 요소를 보완해 다시 만든 것이 아래의 그림이다. Intel의 오리지날의 그림이 부족하고 있던 만큼 기예측이나 SMT(Simultaneous Multithreading)는, 그림에 반영하고 있지 않다.
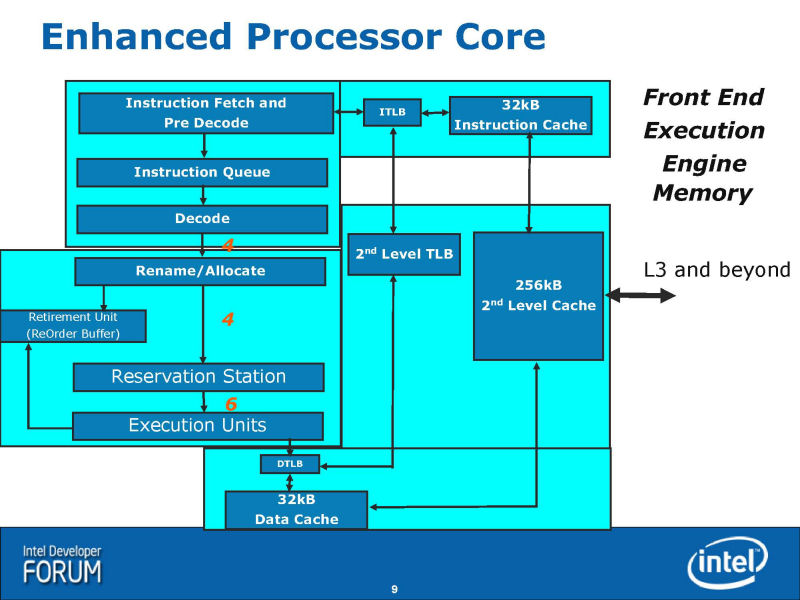
Nehalem의 블럭도를 언뜻 봐 깨닫는 것은, Core MA의 블럭도와의 유사성이다. Core MA의 블록 다이어그램을 Nehalem에 맞추고, Intel의 오리지날의 그림으로부터 다소 변경한 것이 아래의 그림이다. 양쪽 모두의 그림으로 묘사가 통일되어 있지 않은 부분(TLB의 표현등)은, Intel가 나타내 보인 각각의 CPU의 오리지날의 블럭도에 준하고 있다. 표현상의 차이로, 기능적인 차이를 이것으로 나타내고 있는 것은 아니다.
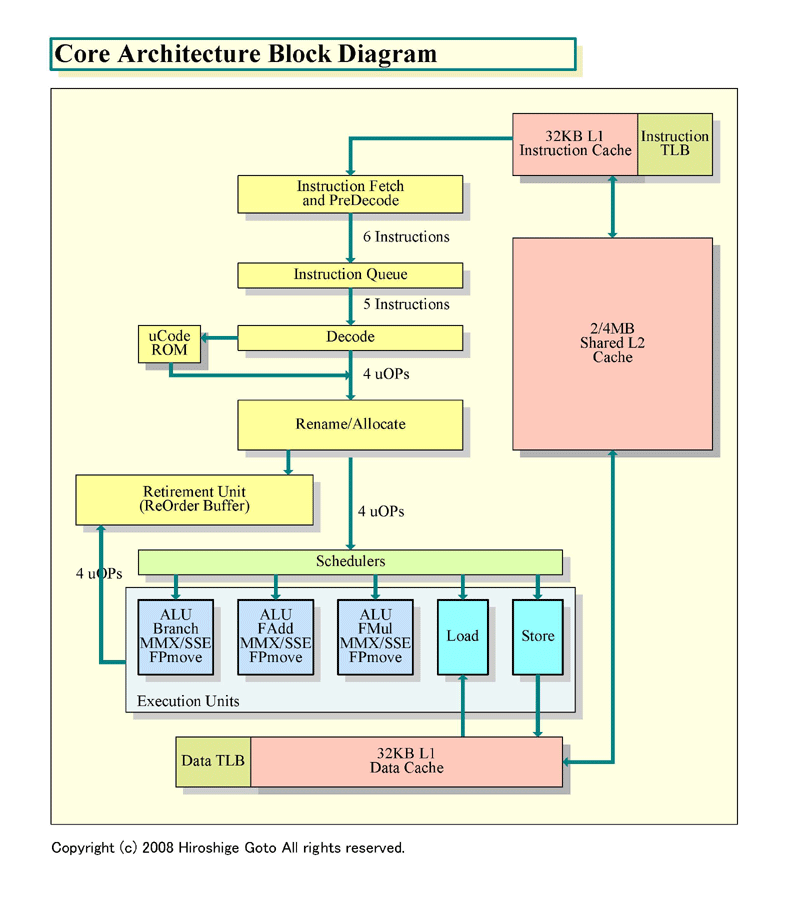
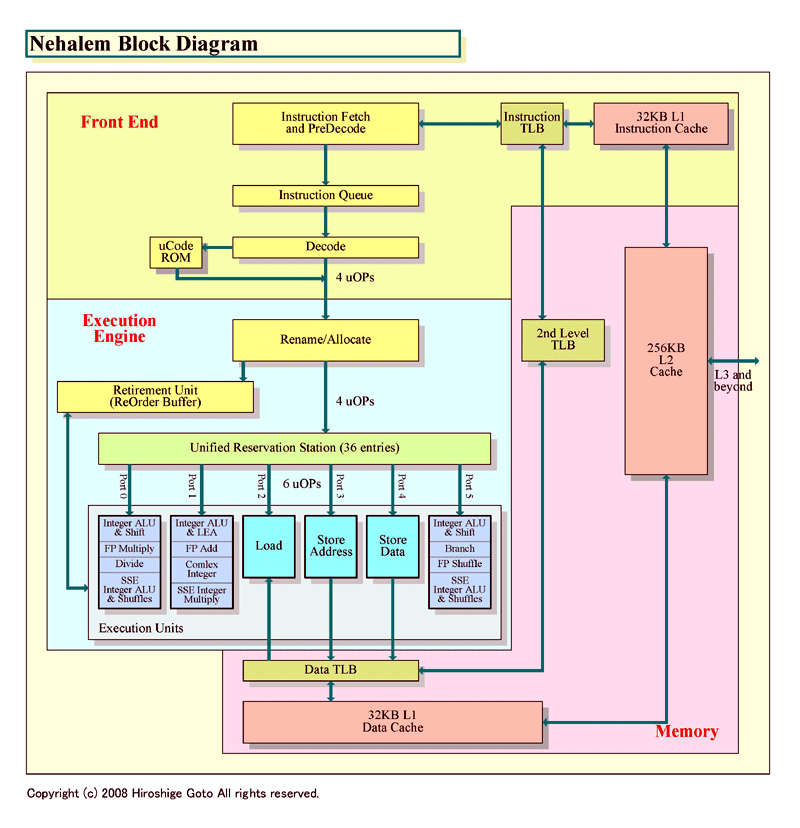
2개의 그림을 봐 비교하면, 유사성은 명료하다. 전체의 구성은 잘 비슷하다. 이것은, CPU 마이크로 아키텍쳐를 관철하는 필로소피가 공통되고 있는 일도 의미하고 있다.
● Pentium 4 개발 센터인것 같은 개량이 더해진 프론트엔드
위에서 보고 가면, 우선, 프론트엔드 회전은 유사성이 특히 강하다. 디코더로 x86 명령을 1 사이클로 최대 4 명령 디코드하고, 내부 명령인「uOPs(micro-operations: 마이크로 작품)」로 변환한다. NetBurst(Pentium 4)에서는, 디코드시에 x86 명령을 섬세한 오퍼레이션에 분할해 버린다. 그에 대하고, Core MA에서는, 복수의 uOPs가 융합한 형태의「Fused-uOPs(퓨즈드 uOPs)」에, 거의 1대 1으로 변환한다. Intel는, 이것을「Micro-OPs Fusion」라고 부르고 있지만, Nehalem에서도 이 특징은 그대로 계승된다.
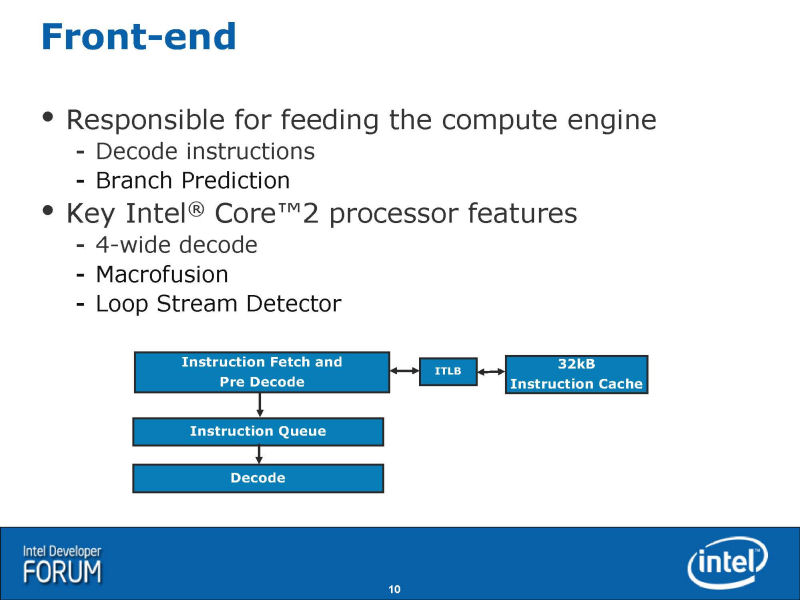
Core MA에서는, 특정의 x86 명령의 페어를 1개의 Fused-uOP에 융합시키는 Macro-Fusion도 실장되었다. Nehalem에서는, 이 기능도 계승하지만, 약간 확장하고 있다. Macro-Fusion 할 수 있는 명령의 편성이 늘려졌다. 또, Core MA에서는, Macro-Fusion는 32-bit 모드시 밖에 enable 되지 않았지만, Nehalem에서는 64-bit 모드시에도 Macro-Fusion 되게 되었다.

Nehalem를 개발한 것은, NetBurst를 개발한 오리건주 힐즈고물의 개발 팀이다. 그 때문에, Nehalem에는 군데군데, NetBurst를 방불과 시키는 기능을 볼 수 있다. 그 1개가「Loop Stream Detector(LSD)」이다. 루프로 같은 명령군이 반복해 실행되는 경우, Loop Stream Detector는, 명령어 인출과 분기 예측을 우회도로 하고, 벌써 페치 되어 있는 루프내의 명령을 반복해 실행시킨다. 명령어 인출과 분기 예측의 로스가 없어져, 퍼포먼스가 오른다.
Core MA에서는, Loop Stream Detector는, 명령 디코더의 전이 되어, x86 명령을 버퍼 하고 디코더에 보내고 있었다. 그에 대하고, Nehalem에서는 Loop Stream Detector가 명령 디코더의 뒤에 있어, uOPs를 스톡 한다. 그 때문에, x86 아키텍쳐의 최대의 관문인 명령 디코드를 우회도로 해, 퍼포먼스를 끌어올릴 수 있다. 아래의 도화 Core MA의 Loop Stream Detector, 더욱 그 아래의 도화 Nehalem의 Loop Stream Detector다. 디코더의 우회도로는, NetBurst의 기본 필로소피이며, Nehalem에서는 일부에 그것이 살려지고 있다.
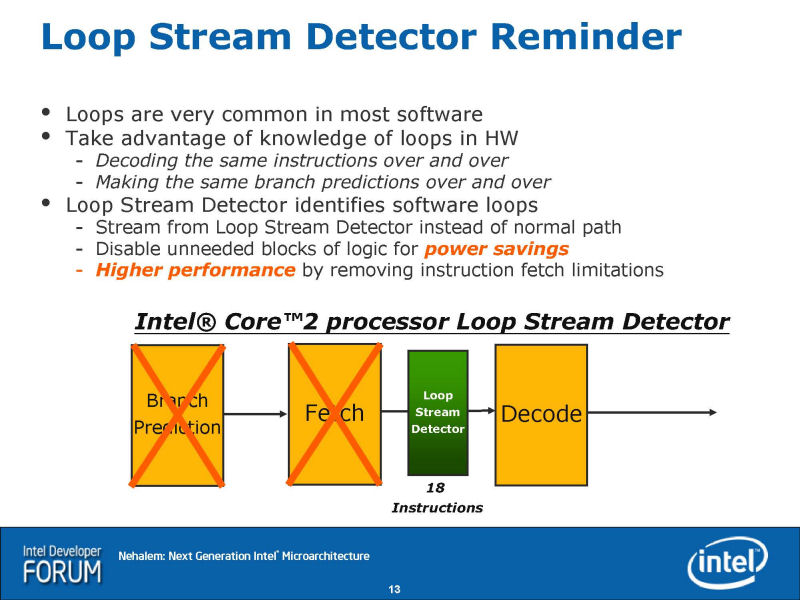
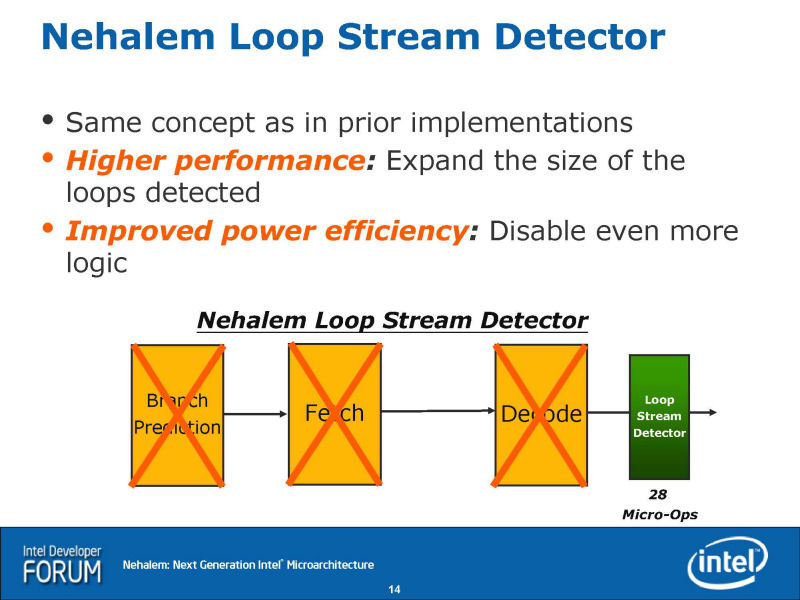
분기 예측에서는 2 레벨의「Branch Predictor와「Renamed Return Stack Buffer (RSB)」이 실장되었다. 이것은, IDF의 프리뷰컨퍼런스의 설명대로다.


● 명령 발행 포토는 5에서 6으로 증가
Nehalem의 EXEC 엔진도 Core MA보다 강화되었다. EXEC 엔진에 명령을 발행하는 포토수가, Core MA의 5로부터 Nehalem에서는 6 포토에 증가한다. 즉, 명령 스케쥴러는 최대 6 uOPs를 실행 유닛군에게 보낼 수 있다. Core MA에서는 최대 5 uOPs(이었)였다.
6개의 명령 발행 포토는, 3개의 콘퓨테이쇼나르오페레이션과 3개의 메모 리오 페레-숀으로 나누어진다. Nehalem에서는, 부동 소수점 연산 퍼포먼스가 비약하지만, 부동 소수점 연산 유닛 자체가 증가하고 있는 것은 아니다. 부동 소수점 SIMD 연산의 가산은 1 유닛, 곱셈은 1 유닛으로, 모두 128 bit폭. 기본적인 유닛의 구성은 Core MA와 다르지 않다.
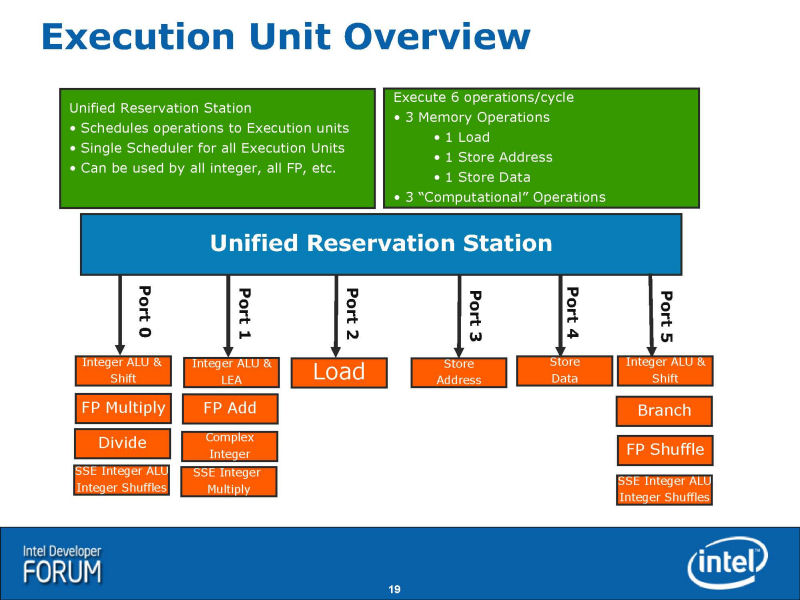
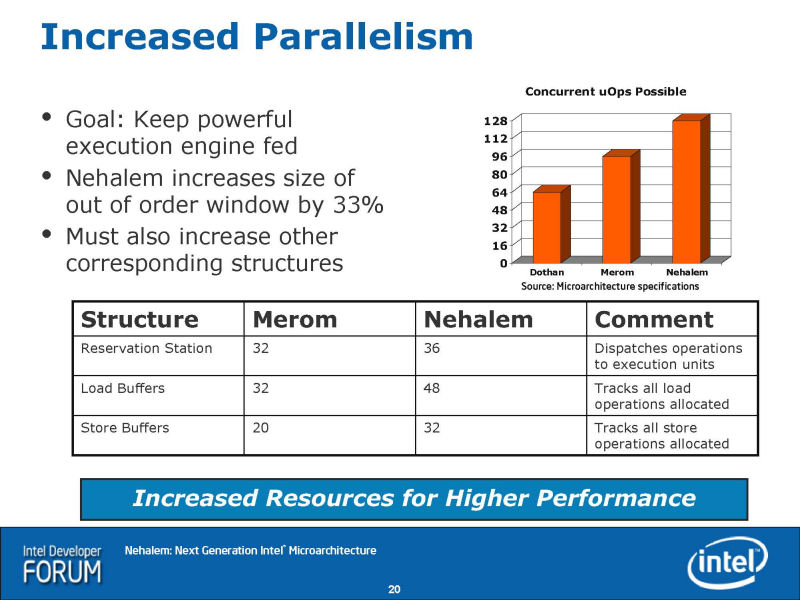
Nehalem로의 개량점은 몇개인가 있다. 하나는, 아웃 오브 오더 윈도우의 확대로, Nehalem는 128개의 uOPs를 온더 플라이로 제어할 수 있다. Core MA에서는 96개(이었)였다. Nehalem에서는, 그 이외의 버퍼도 깊어지고 있다. 리져베이션 스테이션이나 로드 버퍼와 스토어 버퍼는, 모두 Nehalem로 엔트리수가 늘려지고 있다.
Nehalem로 가장 큰 확장 포인트의 하나는, SMT(Simultaneous Multithreading)다. Hyper-Threading와 같이, 2개의 스렛드를 1개의 CPU 코어로 달리게 할 수 있는 SMT가 Nehalem에는 실장되고 있다.
Intel로 Nehalem 개발을 담당한 Ronak Singhal씨에 의하면, Nehalem로의 SMT 개발에 종사한 것은, NetBurst에 SMT를 실장한 것과 같은 팀이라고 한다. 그 때문에, 피로소피는 같고, Nehalem에서는, 메모리 대역의 여유가 증가한 만큼, SMT에 의한 성능 향상이 보다 현저하게 된다고 한다. Nehalem의 SMT는, CPU 코어 부분의 다이 면적의 5~10%의 증가분으로 실현되고 있어 매우 퍼포먼스/소비 전력의 효율이 좋다고 한다.
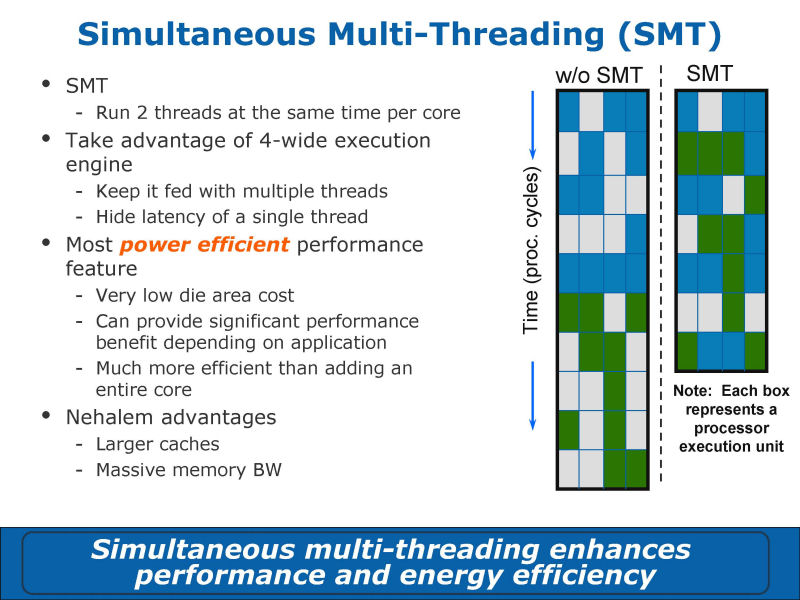

메모리 회전도 Nehalem에서는 강화되었다. 물리 메모리아드레스를 캐쉬하는「Translation Lookaside Buffer (TLB)」은 2 계층화 된다. 안 아라인(unaligned) 캐쉬 액세스의 고속화와 multi-thread 어플리케이션으로 중요해지는 동기 원시적의 고속화도 실현된다.
● 낮은 Nehalem의 메모리아크세스레이텐시
Nehalem에서는, L1, L2, L3의 3 계층의 캐쉬 구성이 되었다. 각 CPU 코어마다 32 KB의 L1명령 캐쉬와 L1데이터 캐쉬, 거기에 256 KB의 전용 L2캐쉬를 갖춘다. 게다가 3층눈으로서 CPU중의 모든 CPU 코어로 공유하는 대용량의 L3캐쉬를 갖추는 구성이 된다. Singhal씨에 의하면, 각 CPU 코어 점유의 L2캐쉬를 도입한 이유는, 지연시간의 저감과 스케이라비리티이기 때문에라고 한다. 캐쉬를 소용량화하는 것으로 고속 액세스를 가능하게 해, 스케이라비리티에 의한 제품의 차별화는 L3의 양으로 조정한다.
Nehalem에서는, CPU에 메모리인타페이스를 통합한 것으로, 메모리아크세스레이텐시는 극적으로 감소했다고 한다. Nehalem에서는, CPU에 직결된 DRAM에 액세스 하는 경우 뿐만이 아니라, 멀티 프로세서 구성으로 다른 CPU에 접속된 DRAM에 액세스 하는 경우도 지연시간이 비교적 짧다고 한다. 아래가 그 차트로, 현재의 서버 CPU「Harpertown」라고 비교하면, 멀티 프로세서의 다른 CPU의 메모리에 액세스 하는 원격 접근으로조차, 보다 고속으로 있는 것을 알 수 있다.



Nehalem로 CPU끼리를 직결하고 있는 것은, 새로운 고속 인터커넥트 QuickPath Interconnect(QPI)다. QPI에 실장되었다고 말해지는, 새로운 캐쉬 coherency 프로토콜「MESIF」에 대해서는 이번은 설명이 없었다. 덧붙여서, 전회의 MESIF의 설명으로는, 겉(표)의 일부가 빠져 있었다. 정확하게는 아래의 겉(표)가 된다.
| Cache line states | |||||
|---|---|---|---|---|---|
| state | clean/dirty | write | forward | transition to | |
| M | modified | Dirty | OK | OK | |
| E | exclusive | Clean | OK | OK | M, S, I, F |
| S | shared | Clean | No | No | I |
| I | invalid | - | No | No | |
| F | forward | Clean | No | OK | S, I |
Nehalem에서는, 가상화때의 지연시간도 저감 되어 고속화를 도모되고 있다. 「Virtual Processor ID (VPID)」와「Extended Page Table (EPT)」이 실장되었다. Nehalem에서는, 새롭게 SSE4의 쌓아 잔재의 명령군이「SSE4. 2」(으)로서 실장된다. 모두, 매우 복잡한 처리의 명령군으로, CPU 내부에서 마이크로코드에 의해 일련의 uOPs군에게 분해된다고 추정된다.
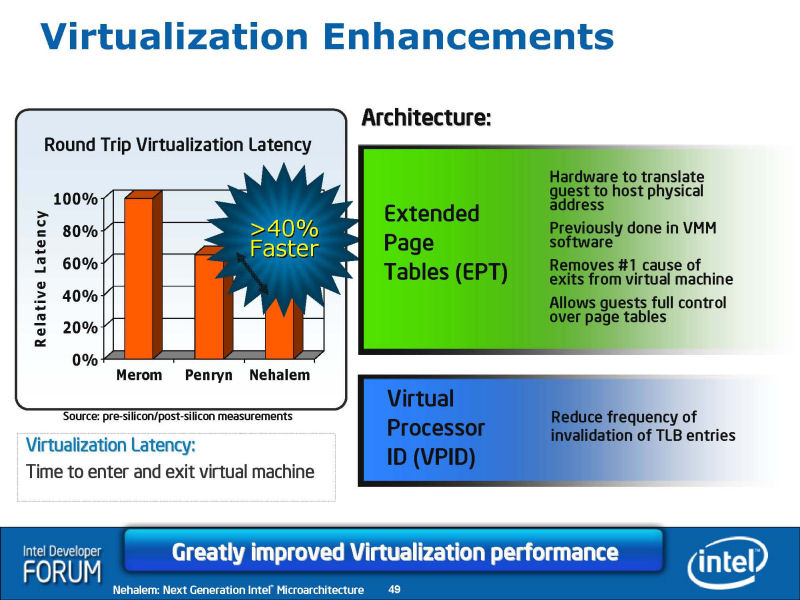
IDF로 밝혀진 Nehalem의 개요를 보면, Core MA시와 같이 큰 전환은 없기는 하지만, 매우 많은 테크닉이 집대성 되고 있는 것을 알 수 있다. 인터페이스 회전의 개량에 눈을 빼앗기기 쉽상이지만, CPU 내부의 아키텍쳐 확장도 매우 다방면에 건너고 있다. 견실하게 퍼포먼스를 끌어올린, 마이크로 아키텍쳐다.
'IT/Hardware > CPU/MB' 카테고리의 다른 글
| [CeBIT 2010] Socket H2(LGA1155) 2011년 1분기 등장 (1) | 2010.03.09 |
|---|---|
| [CeBIT 2010] 인텔 6코어 걸프타운(Gulftown) 시연회 (0) | 2010.03.09 |
| 인텔 초코파이쿨러 또 바뀐다. (0) | 2010.03.08 |
| CPU GTL전압에 대한 이해 (0) | 2009.08.15 |
| 인텔 E5200 R0 스테핑 오버클럭 사용기 (0) | 2009.04.23 |
| CPU 캐쉬용량에 따른 성능차이 (0) | 2009.03.15 |
| E5200 말레이시아 B코드 (0) | 2009.02.17 |
| 차세대 USB 3.0 발표 (0) | 2008.11.19 |
| 인텔, Core i7 정식발표 (0) | 2008.11.19 |
| Intel, IDF에서 Atom 프로세서를 정식 발표 (0) | 2008.11.17 |



댓글