반응형
●199 달러의 비디오 카드에 최적인 GPU 아키텍쳐
NVIDIA 는, 199 달러 가격대를 타겟으로 한 퍼포먼스 GPU「GeForce GTX 460(GF104)」을 발표했다.200 달러 전후로부터 200 달러대의 가격대는, PC게이머에게 있어서의 구매욕구를 불러일으킨다, GPU 벤더인 NVIDIA에 있어서는 최대중요의 시장이다.GF104는, 거기로 향한 제품이기 위해, NVIDIA라고 해도 힘이 들어가고 있다.그래픽스 전용으로서의, Fermi 아키텍쳐의 평가를 굳히는 제품이 되기 때문이다.
NVIDIA 는, 게이머를 타겟으로 한 GF104를, 어떻게 고급 지향의「GeForce GTX 480(GF100)」아키텍쳐로부터 파생시켰는가.동사는 몇개의 중요한 결정을 행했다.그것은, Fermi 아키텍쳐의 프로그래밍 모델상의 일관성을 유지하면서, 그래픽스의 퍼포먼스 효율을 올리는 것.그리고, 그 때문에(위해), 그래픽스 부하에 맞추어 내부 마이크로 아키텍쳐를 재설계하는 것(이었)였다.

G80로부터 GF100까지의 변천

우선 NVIDIA는, 연산 프로세서군의 최소단위인「Streaming Mutliprocessor(SM)」의 내부의 연산 유닛군을, 그래픽스 부하에 적절한 비율에 재구성했다.특히, 연산 프로세서인 CUDA 코어의 수를 늘리고, GPU의 프로세싱 퍼포먼스를 확장했다.거기에 맞추어 명령 발행을 확장해, 피크의 IPC(Instruction-per-Clock)를 높였다.그 한편, ECC를 생략해, CUDA 코어를 단정도 연산 중심으로 변경하는 등의 그래픽스 최적화에 의해서, SM의 실장을 가볍게 했다.그 결과, GF104는, 상위의 GF100보다 그래픽스시의 퍼포먼스 효율의 높은 GPU가 되었다.
이러한 확장을 행하는 한편으로, NVIDIA는 Fermi의 아키텍쳐상의 특징을 보관 유지했다.우선, 공유 메모리의 양이나 배정도 명령의 유무 등, 프로그래밍에 관련되는 부분은 모두 상위의 GF100와 가지런히 했다.또, 캐쉬 계층과 같이, 최적화로 중요해지는 요소도 GF100와 공통화했다.SM 마다의 테셀레이터나 복수개의 래스터라이저라고 한, Fermi의 중요한 그래픽스 기능도 남겨졌다.그 결과, GPU 컴퓨팅과 그래픽스의 양면에서, 프로그래밍상의 호환성은 거의 완전하게 유지되었다.
NVIDIA 의, 이 아키텍쳐 선택에는, 의문이 남는 부분도 있었다.그것은, SM의 연산 능력과 IPC를 높였는데, 스레드스케줄링을 확장하지 않았던 것이다.NVIDIA GPU가 종래 행해 온, 멀티스레딩에 의한 메모리레이텐시 은폐의 능력이 GF104에서는 저하되고 있다.그러나, 이것에도 합리적인 이유가 있다.그것은, GPU가 세대와 함께, 자꾸 메모리 대역에 의해서 제약되는 점이다.이것은, 과거수세대의 NVIDIA GPU의 연산 자원과 메모리 대역의 신장 비율을 비교라고 보면 잘 안다.메모리 대역은, GPU라고 하는 프로세서에 있어서 최대의 벽이며, NVIDIA는 그에 대하고, 데이터의 국소성을 적극적으로 이용한다고 하는, 정통적인 수법으로 대응하려고 하고 있다.

●16 CUDA 코어의 클러스터를 3개 갖춘 SM
NVIDIA GPU의 최소단위인 SM의 마이크로 아키텍쳐를 상세하게 체크하면, GF104의 정체가 보여 온다.GF104의 SM를 GF100와 비교시에, 곧바로 눈에 띄는 것은 유닛군의 확장이다.특히, 연산 프로세서인 CUDA 코어는, GF100의 32개로부터 GF104에서는 48개에 확장되고 있다.Fermi 아키텍쳐에서는, CUDA 코어는 16 개씩이 1개의 연산 클러스터에 바인드 되고 있어 GF104에서는 그것이 3 클러스터에 증가하고 있다.이 외 , Special Function Unit(SFU)는 4개로 1 클러스터(이었)였던 것이 8개로 1 클러스터가 되어 있어, texture 유닛도 마찬가지다.
SM 의 내부 구조를 보고 아는 대로, 실행 유닛은 모두 32의 약수로 클러스터를 구성해 있다.명령 실행이 32 스렛드의 WARP 단위로 행해지기 때문이다.WARP는「SIMT(Single Instruction, Multiple Thread)」실행, 즉 같은 명령을 실행하는 스렛드의 다발로, 일반적인 벡터 머신의 벡터장에 해당한다.그리고, G80 이래, NVIDIA GPU의 WARP 사이즈는 32 스렛드로 고정되고 있다.
각 실행 유닛 클러스터는, 1개의 WARP를 수사이클 throughput로 실행한다.예를 들면, 16개의 CUDA 코어는 2 사이클 throughput로 1개의 WARP(32 스렛드)를 실행한다.이와 같이 8개의 클러스터는 4 사이클 throughput, 4개의 클러스터는 8 사이클 throughput으로 실행한다.2개로 16 사이클, 1개로 32 사이클, 32개로 1 사이클이라고 하는 구성도 가능하다.
역을 말하면, NVIDIA 아키텍쳐에서는, 각 실행 유닛 클러스터는, 32를 나뉘어 떨어지는 한, throughput와 유닛의 병렬도의 사이에 자유로운 구성을 취할 수 있다.실행 유닛 클러스터의 구성을 4에서 8또는 16으로 확장해도, 명령 throughput가 바뀌는 것만으로, 기본적으로는 그 이외의 제약이 없다.
그 때문에, NVIDIA는, 비교적 자유롭게 클러스터의 유닛 구성을 바꿀 수 있다.컴퓨터 아키텍쳐적으로 말하면, 논리 벡터장은 32에 고정되고 있지만, 물리 벡터장은 자유롭게 변경할 수 있는 것이 NVIDIA 아키텍쳐의 특징이다.다음 번의 기사로 설명하는 WARP 스케줄링이 유연성이 풍부하고 있기 때문에, 이러한 자유로운 구성이 가능하게 되어 있다.

GF104로의 WARP의 스케줄링
●실장상은 크게 다른 GF104의 CUDA 코어
GF104 아키텍쳐로의 CUDA 코어는, 실은 GF100의 CUDA 코어와 다르고 있다.GPU의 연산 유닛은, 부동 소수점적화연산(MAD) 유닛이며, 정수 연산 파이프도 갖추고 있다.종래의 GPU의 연산 파이프는 단정도 부동 소수점 연산 전용(이었)였지만, GPU의 범용(General Purpose) 이용이 퍼지는 것에 따라 변화해 왔다.
NVIDIA 는, 전생대의「GeForce GTX 280(GT200)」에서는, 8개의 단정도 유닛에 대해서 1개의 비율로, 배정도 연산 전용의 MAD 유닛을 실장했다.다음의 GF100의 CUDA 코어에서는, 32 유닛 모두에 배정도 연산 기능을 갖게했다.GF100의 배정도 연산은, Tesla 버젼의 경우, 피크의 연산 능력이 단정도의 것1/2되고 있다.데이터 패스 등에 제약이 있기 위해, 배정도 연산 명령을 발행할 때 , 다른 명령을 발행할 수 없기 때문에 피크 성능이 제약되고 있다.그 제약을 제외하면, GF100 CUDA 코어는 풀의 배정도 연산 능력을 가지기 위해, 연산 유닛 자체의 실장 코스트는 꽤 비싸다고 추측된다.
GF100 다이는 HPC 제품인 Tesla를 중요 타겟으로 했기 때문에, 이 실장으로 좋았다.그러나, 그래픽스 시장을 메인 타겟으로 하는 GF104에서는, 그러한 실장은 너무 무겁다.배정도 연산에 트랜지스터를 할애해도, 소용 없게 되어 버리기 때문이다.거기서, NVIDIA는 GF104의 CUDA 코어에서는, 실장 코스트를 꽤 억제한 배정도 부동 소수점 연산을 서포트를 행했다.
우선, GF104 SM의 3개의 CUDA 코어 클러스터 가운데, 2 클러스터는 완전하게 단정도 연산 전용 MAD가 되고 있다.그 때문에, 이 신CUDA 코어의 부동 소수점 연산 파이프에 대해서는, Fermi 이전의 NVIDIA 아키텍쳐에 가깝다고 추측된다.즉, 48개의 CUDA 코어중, 32개는 그래픽스 전용의 단정도 MAD다.
또, 배정도 연산을 서포트하는 1개의 CUDA 코어 클러스터에 대해서도, 실장은 그만큼 무겁지는 없다고 추측된다.GF104의 배정도 연산 서포트 클러스터가,1/4의 배정도/단정도 연산 throughput비이기 때문이다.즉, 16개의 CUDA 코어가, 단정도의 경우의 것1/4한 throughput로 배정도 연산을 행한다.1개의 WARP의 실행 throughput는 8 사이클이 되는 계산이다.
1/4 그렇다고 하는 throughput비는, AMD( 구ATI) 아키텍쳐로의 배정도 서포트와 같다.AMD 아키텍쳐에서는, 4개의 단정도 연산 유닛을 사용해 1개의 배정도 연산을 행한다(AMD는 1개의 VLIW 프로세서내에 5개의 단정도 연산 유닛을 갖추기 위해, 실제로는1/5의 비가 된다).AMD는, 그 어프로치로의 실장상의 코스트는 매우 가볍다고 설명하고 있었다.GF104의 배정도 서포트 CUDA 코어도 비슷한 수법을 취하고 있다고 보여진다.즉, 배정도 연산을 서포트하지만, 연산 유닛의 실장 코스트는 AMD와 같이 가볍다고 볼 수 있다.

ATI RV770 VLIW 프로세서의 구조
●개발 플랫폼으로서의 그래픽스 제품을 고려
배정도 연산을 서포트하는 CUDA 코어 클러스터는, 단정도의 것1/4한 throughput로 배정도 연산을 행한다.1/3의 CUDA 코어 클러스터가,1/4의 throughput로 배정도 연산을 서포트하기 위해(때문에), SM전체로의 배정도와 단정도의 피크 성능의 비율은1:12되고 있다.즉, 각 SM 마다, 1 사이클에 4개의 배정도 부동 소수점 연산이 가능하다.
그 때문에, 배정도 퍼포먼스는, SM 당 동클락의 GF100의 것1/4된다.꽤 낮은 것처럼 보이지만, 그런데도 7 SM가 유효하게 되어 있는 GF104라면, 칩 전체로 75.6 GFLOPS(1.35 GHz시)의 배정도 연산 퍼포먼스가 된다.8 SM로 1.35 GHz시에는 86.4 GFLOPS다.이것은, 종래의 GeForce GTX 280(GT200) 계와 거의 동레벨의 배정도 연산 성능이다.
NVIDIA 가1/12의 퍼포먼스비(이어)여도 배정도 연산을 서포트한 것은 중요한 의미를 가지고 있다.배정도 연산을 서포트하기 위해(때문에), GF104는 실행 가능 명령종에서도 상위의 GF100와 거의100%의 호환성을 가진다.종래의 퍼포먼스 GPU로부터 아래의 라인 업은, 배정도 연산을 서포트하지 않고 상위 GPU와의 호환성은100%는 아니었다.그러나, GF104는 GF100와 풀의 호환성을 가진다.이것은, GF104에, 범용적인 프로그램의 개발 플랫폼으로서 중요한 의미를 갖게한다.
NVIDIA로 GeForce 제품을 통괄하는 Drew Henry씨(General Manager, GeForce GPUs, NVIDIA)는 다음과 같이 설명한다.
「배정도 연산 기능을 저가격의 제품에도 가져온 이유는, 개발 플랫폼으로서 중요하게 되기 때문이다.당사는, 고급 지향의 Tesla 제품을 향해서 코딩 하는 우리의 고객의 요구를 이해하고 있다.그들은, 그래픽스 제품을 저가격의 개발 플랫폼으로서 사용해, 그 프로그램을 HPC(High Performance Computing) 제품으로 달리게 한다.우리는, 그러한 요구에 응하는 것이 필요하다고 생각했다」.
GPU 프로그래머는, 풀 스피드로 달리지 않아도, 배정도 연산 명령을 포함한 코드를, 그래픽스 제품으로 달리게 하고 시험할 수 있다.그 위에, 같은 프로그램을 HPC 제품 위에서 달리게 할 수 있다(멀티 GPU 전개의 부분은 별도로).균일의 명령 세트 아키텍쳐로의 프로세서의 스케일라비리티가 가져오는 이점이다.같은 이점은, 지금 현재, x86 CPU가 가지고 있다.
NVIDIA 간부의 말에서는, 동사가, 이 이점을 중요하다고 인식하고 있는 것을 알 수 있다.이점을 이해한 다음, GPU 제품을 패밀리로서 일관성이 있는 개발 플랫폼으로 하려고 하고 있다.NVIDIA가, GPU 컴퓨팅의 이점을 충분히 이해하고 있는 것이 방문한다.NVIDIA가, 그래픽스 디바이스가게로부터 컴퓨터 메이커로 전환하고 있는 것이 상징되고 있다.
이렇게 해 보면, NVIDIA는 최소의 실장 코스트로, 부동 소수점 연산의 일관성을 GF104로 유지하는 길을 찾아낸 것을 알 수 있다.
●보다 파워풀한 64 CUDA 코어의 구성도 검토
NVIDIA는 GF104의 SM에 대하고, SFU 클러스터나 texture 유닛 클러스터의 구성도 변경했다.
초월 함수등의 실행 유닛인 SFU는, GF100에서는 4개로 1 클러스터(이었)였지만, GF104에서는 8개로 1 클러스터의 구성이 되고 있다.그 때문에, 명령 throughput가 반의 4 사이클이 되었다.보다 많은 명령을 발행할 수 있을 여유가 출생한다.texture 유닛도 이와 같이 2배에 강화되었다.texture 주소 생성 유닛과 texture 필터링 유닛의 어느쪽이나 배증되고 있다.
이것들 유닛군의 증강은, 그래픽스 부하시의 명령 믹스의 분석에 근거해 행해졌다고 한다.이것은, 아래의 그림으로 NVIDIA GPU 패밀리의, SM 또는 Texture/Processor Cluster(TPC) 당의 각 유닛수의 변화를 보면 잘 안다.
순수하게 그래픽스를 위한 제품(이었)였던 NV40 세대로는, GPU의 내부 구성은 아래의 그림과 같이 되어 있었다.범용의 적일본 재래의 주산(MAD) 유닛에 대한, SFU와 테키스체유닛트의 비율은 세대마다 작아지고 있어 GF100에서는 전에 없이 MAD의 비율이 높아지고 있다.GF104는, 그 비율을 그래픽스 집합에, 흔들어 되돌리고 있다.
NVIDIA 로 GPU 엔지니어링을 담당하는 Jonah M. Alben씨(Vice President, GPU Engineering)에 의하면, Fermi 아키텍쳐의 확장에서는 다른 구성도 검토했다고 한다.CUDA 코어 클러스터를 4개로 하고, SM 당 64개의 CUDA 코어를 탑재하는 구성이다.그러나, 실제의 코드에서는, 적일본 재래의 주산만이 집중적으로 연속하는 경우는 적고, 다른 명령도 믹스 되는 케이스가 많았다고 한다.그 때문에, 현재의 GF104와 같은 구성에 침착했다고 한다.

NVIDIA GPU_Processor Cluster의 유닛수비교
●그래픽스 기능은 그대로 GF100로부터 계승
Fermi 아키텍쳐에서는, DirectX 11의 Direct3D11 서포트를 위해서, 평면 분할 전용 하드웨어의 테셀레이타가 SM 마다 1 유닛씩 실장되고 있다.이것은 GF104의 SM에서도 그대로 계승해지고 있다.NVIDIA는, 테셀레이타를 포함한 지오메트리파이프라인계의 고정 기능 유닛군을「PolyMorph Engine(포리모후 Engine)」라고 부르고 있다.NVIDIA로부터의 정보를 바탕으로 추측한 GF104의 SM구성도에서, 위에 배치한 것이 PolyMorph Engine다.
그림중으로 PolyMorph Engine의 배치가 적당인 것은, 단지 블럭도상에 배치할 만한 정보가 NVIDIA로부터 얻지 못하고 있기 때문이다.통상, GPU의 블록 다이어그램도는, 데이터 플로우를 중심으로 만들어져 있다.GPU에서는 명령의 플로우보다, 데이터의 흐름이 훨씬 중요하기 때문이다.
그러나, 위의 그림은, 컴퓨터 아키텍쳐적으로 알기 쉽게 설명하기 위해서, 데이터 플로우와 명령 플로우의 양쪽 모두를 그리고 있다.그러나, Fermi 아키텍쳐의 SM의 데이터 플로우에는, 아직 모르는 부분이 있어, 확실한 그림을 만드는 것이 아직 되어 있지 않다.그 때문에, 데이터 플로우 위에 배치해야 할 , 테셀레이타나 바 옷감 페치를 그림중으로 정확하게 배치할 수 없다.
원래, PolyMorph Engine에 포함되는 기능 블록은, 1개에 결정되고 있는 것은 아니다.그 뿐만 아니라, 이름만의 불명료한 것도 있다.예를 들면, 스트림 아웃은 프로세서 코어로부터 메모리에의 다이렉트인 써, 즉, ROP(Rendering Output Pipeline)등을 개의치 않는 메모리 기입의 패스를 의미하고 있다.SM의 기구상, 이 기능은 실질적으로는 로드/스토어 유닛이 담당하고 있을 것이다.즉, 스트림 아웃은, 로드/스토어 유닛이 실현되고 있는, 그래픽스 파이프라인상의 기능이다.
그런데도, 왜 그것이 PolyMorph Engine(분)편에 들어가 있는 것인가.그것은, 스트림 아웃이, 지오메트리파이프라인안의 DirectX의 기능의 하나이기 위해라고 추측된다.즉, PolyMorph Engine는, DirectX 지오메트리파이프라인으로의 시다프로셋사 관계 이외의 기능을 개념적으로 집계한 것이며, 그 이상 의 것은 아니다.위의 그림에서는, 그 때문에 PolyMorph Engine 부분에 대해서는 애매하게 한 배치로 해 있다.
GF104의 SM의 이러한 유닛은, 실제로는 어떻게 움직이는 것인가는 다음에 알아보도록 하자.
반응형
'IT/Hardware > Graphics' 카테고리의 다른 글
| AMD Radeon HD6870 분해 리뷰 (1) | 2010.10.22 |
|---|---|
| AMD, DX11 2세대 Radeon HD6870 발표 총정리 (0) | 2010.10.22 |
| AMD, ATI브랜드 버린다. (0) | 2010.08.31 |
| XFX HD5970 4GB Black Edition 프리뷰 (1) | 2010.08.29 |
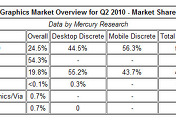
| ATI, 엔비디아 제치고 시장점유율 1위 달성 (0) | 2010.08.04 |
| NVIDIA GeForce GTX 460 아키텍처의 숨겨진 비밀 1부 (0) | 2010.07.31 |
| ASUS ARES 4GB 리뷰 (2) | 2010.07.08 |
| Adobe Flash Player 10.1.53.64 정식발표 및 개선내용 (0) | 2010.06.11 |
| ATI HD6000 차세대GPU 로드맵 등장 (0) | 2010.05.31 |
| ASUS Radeon EAH5870 Matrix Platinum 2GB 리뷰 (0) | 2010.05.18 |



댓글